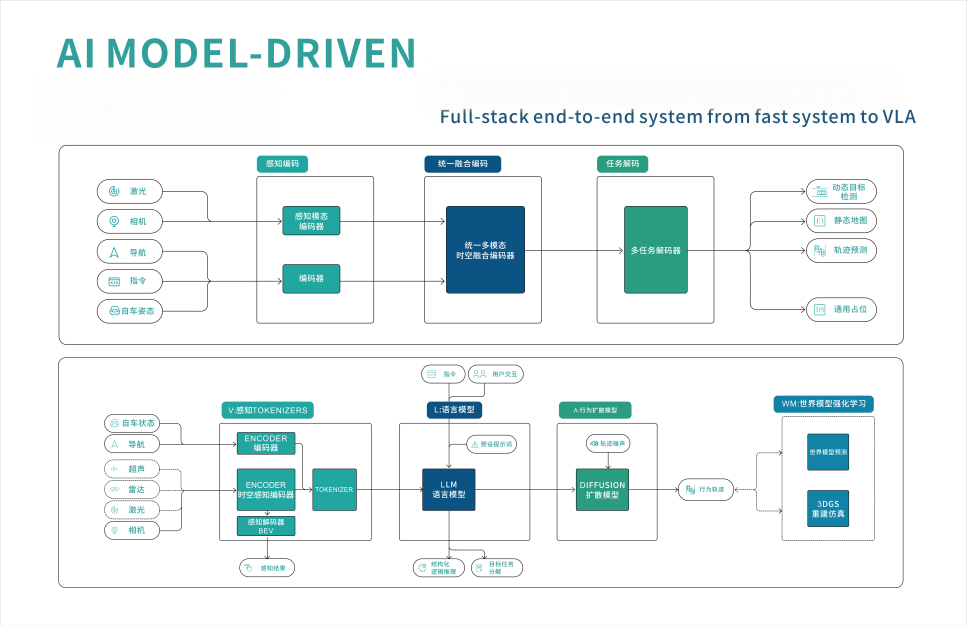
Core Technologies
Contact Us
Products and Services
Contact Us
About Us
Contact Us
News
Contact Us
Contact Us
Contact Us